Není korpus jako korpus
Pavel Baránek
Často se v našich příspěvcích odvoláváme na data z „korpusů“. Ačkoliv mohou lingvisté působit zvláštně, když hovoří o korpusech v jiných než kulinářských souvislostech, není důvod pochybovat o jejich příčetnosti. Korpus je totiž opravdu lingvistický terminus technicus. Co ale korpusy jsou a jak fungují?
Zjednodušeně řečeno, korpusy jsou velké databáze textů (psaných i mluvených; historických i současných) určitých jazyků. Největší korpusy obsahují miliardy slov, existují ale i korpusy menší nebo různě specializované (např. Pražský mluvený korpus). Pro jazykovědné bádání je podstatné, že neobsahují jen slova samotná, ale také jejich popis jejich gramatických vlastností – slovní druh, číslo, rod apod. Na základě všech těchto kritérií můžeme v korpusech vyhledávat.
V českém prostředí se nejčastěji setkáte s korpusy pocházejícími z Ústavu Českého národního korpusu (www.korpus.cz). Nejčastěji se pro lingvistickou práci používají korpusy psané češtiny SYN (od slova synchronní, současné) nebo mluvené korpusy ORAL či Ortofon. Můžeme se setkat i s korpusy autorskými, překladovými či historickými. O detailech k jednotlivým korpusům se můžete dočíst ve skvěle zpracované korpusové wiki.
K čemu ale jsou korpusy v praxi? V první řadě je lingvisté používají pro výzkumné potřeby. V dnešní době je standardem, že se existence zkoumaných jazykových jevů dokládá daty z určitého korpusu. Korpusy tak podporují (nebo vyvracejí) naši jazykovou intuici. Ve světě i u nás vznikla řada odborných publikací založených na těchto datech, z českého prostředí jmenujme například publikaci Františka Čermáka Slovník Karla Čapka nebo Mluvnici současné češtiny I. Jak se píše a jak se mluví Václava Cvrčka. Své uplatnění mohou korpusy také nalézt v kontextu vzdělávání a fungují jako základ pro učebnice určené cizincům.
Díky přívětivému rozhraní dostupném na stránkách ČNK není vyhledávání v korpusech a využití přidružených aplikacích vůbec složité a korpusy tak mohou být spolehlivým nástrojem i pro laiky, kteří se chtějí obohatit o jazykové zajímavosti, rozseknout spor o jazykový tvar, potvrdit či vyvrátit existenci různých slov a jejich neobvyklých tvarů. Doprovodné aplikace navíc mohou pomoci při překladu, porovnávání synonym a v dalších situacích, kdy jazyková intuice k přesvědčivému rozhodnutí nestačí.
Že můžou korpusy být zdrojem jazykových zajímavostí se můžeme přesvědčit snadno, zkusme použít aplikaci SyD (korpusový průzkum variant) a vyhledat v mluveném jazyce oblíbené české pokrmy – guláš a řízek. Z mapy zjistíme, že ve všech jazykových oblastech se (na základě korpusů současné mluvené češtiny) mluví mnohem častěji o guláši, pouze ve středomoravské oblasti vítězí řízek:
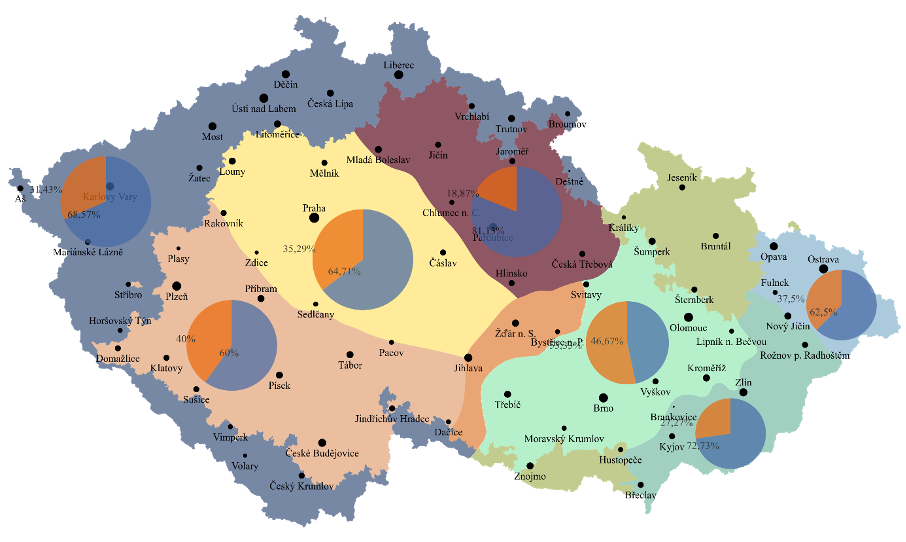
Způsobů vysvětlení může být mnoho, počínaje charakterem, velikostí a rozložením dat v korpusu (záleží na tom, kolik slov máme k dispozici a odkud pochází) přes kulturní kontext až po historický vývoj – tento region byl historicky úzce svázán s Vídní, odkud řízek pochází. Ať je vysvětlení jakékoliv, podobné jazykové jevy vždy přináší podnětnou diskuzi.
Někdo možná namítne, že podobné jazykové hrátky jsou sice zajímavé, ale ne příliš užitečné. Jak jsme ale zmínili, korpusy mohou sloužit i pro praktičtější účely. Kupříkladu aplikace Treq nám může usnadnit práci při překladu textů, umožňuje totiž nahlédnout do rozsáhlé překladové databáze. Když si tedy nevíme rady při překládání, můžeme se inspirovat staršími překlady a porovnat, jak se s hledaným výrazem v různých kontextech poprali překladatelé před námi.
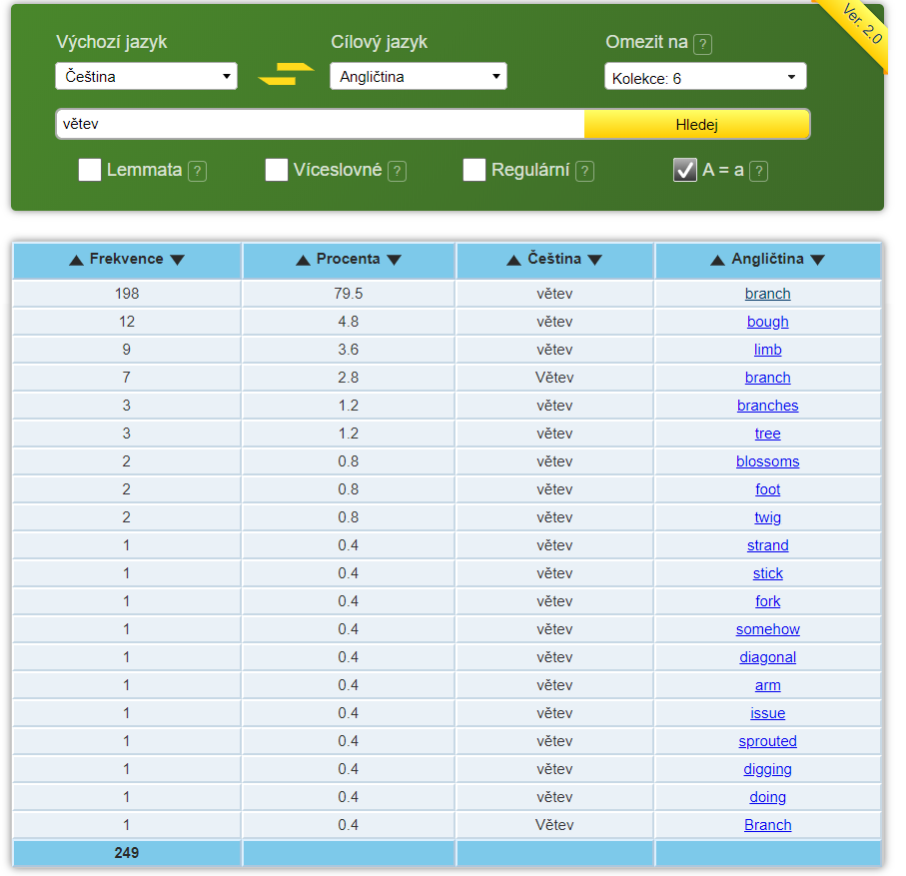

Nač tedy čekat, ať čas v karanténě trávíte produktivně nebo ne, zabavme se jazykovědou!
Lidé jsou, obzvláště ve vztahu k jejich mateřskému jazyku, vynalézaví a hraví. Až vám příště někdo bude tvrdit, že se něco „takhle říká“ nebo že „tohle slovo se píše tak, a ne jinak“, vsaďte se s nimi – korpus vás rozsoudí. Napadá nás: říká se častěji ten image, nebo ta image? Mluvíme častěji o knedlících, nebo o masu?